Afin de fêter la nouvelle année, je relance mon blog avec une série d’articles sur l’hyperconvergence. Ce premier article, en forme d’introduction, me permettra de centraliser les différents sujets qui tourneront autour de la convergence de l’hyperviseur.
Avant d’aborder de manière poussée les différents concepts / produits qui sous-tendent ce sujet, il m’apparait nécessaire de bien définir ce que j’entends par hyperconvergence
- Qu’est-ce que l’hyper convergence ?
L’hyperconvergence, n’est pas une hyper-convergence, une GIGA CONVERGENCE qu’il faudrait voir comme un élément ultime. C’est vraiment dans le sens convergence dans l’hyperviseur qu’il faut le comprendre. L’apparition de l’hyperviseur et son explosion au milieu des années 2000 a imposé de plus en plus de stress au matériel. En effet les concepts qui sous-tendaient l’architecture IT était alors plutôt dédié à du client-server x86 voir à des gros systèmes. Le stockage en particulier par son aspect centralisé et monolithique a longtemps empêché de prévoir un scaleout simple.
Un boitier hyperconvergé, HCI en anglais, est donc un boitier concentrant le compute, le stockage et les liens réseau permettant de se relier au réseau global entreprise. Le noeud d’hyperviseur, voir plusieurs noeuds dans un boitier 2U devient l’élément atomique, la commodities, la cellule dans mon modèle de
datacenter organique.
Il est normal qu’un service de développement logiciel ait besoin pour un projet donnée de mettre en place une infrastructure rapidement afin de commencer à développer ASAP pour répondre à la demande client . Attendre 8 mois pour obtenir une VM car le budget de l’IT a été consommé et qu’il faut racheter une baie de stockage n’est pas envisageable. Que reste-il comme option ? rajouter une VM ? rajouter xVM ? admettons que le projet prenne de l’importance, il faut déployer un environnement de production, de préproduction, de formation, une vitrine. et c’est la lente agonie de l’infrastructure que l’équipe de développement va subir. Cela vient-il de la conception ? de l’infrastructure répartie ? où est le bottleneck ? c’est extrêmement interessant pour l’expert technique de rechercher la cause dans le sens où il va devoir investiguer toute la chaine aller dans le coeur du système, du stockage… mais pour le client final ? et pour le business ? dans tous les cas après l’analyse comment corriger ? qui paye la nouvelle infrastructure ?
- L’hyperconvergence ça vient d’où ?
Les premières tentatives de convergences ont eut pour initateurs CISCO au milieu de sannées 2000. Grâce à des partenariats / joint-ventures avec les 2 leaders du stockage que sont NETAPP et EMC². avec respectivement le FlexPOD et le vBlock, les premières architectures convergentes sont nées. Les idées derrières ces architectures convergées sont louables :
- fournir un matériel testé et dimensionné pour le workload demandé,
- lier le compute, le stockage et le network dans un stack (en général une baie complète),
- proposer un support unique. Au moins au niveau du point d’entrée,
- proposer une architecture éprouvée et validée par un éditeur.
Suite à cela, l’approche dite en bundle a fait beaucoup de bruit fin des années 2000
Seulement cela ne répond pas au besoin. Cela permettait de prévoir plus simplement une charge mais cela ne permettait pas de prendre en compte l’évolution de cette charge. Le coût d’un tel package avec une brique de base de l’ordre de la baie complète est tout sauf anodin ! sans parler de la complexité qui n’était pas si simplement gérée que cela.
- Pourquoi l’hyperconvergence ?
Comme on l’a vu, la virtualisation et l’accélération du delivery qu’elle a imposée aux équipes IT est un élément de réponse. Cependant cela n’explique pas tout selon moi. Une explication qui me semble très pertinente selon moi vient de S.Poitras (ou du moins c’est sur son blog que j’en a pris conscience pour la première fois).
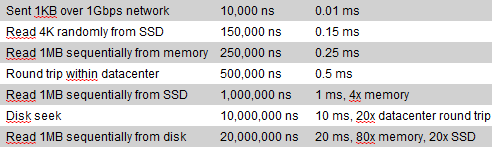
La latence.
Figure 1 : les différentes latences temps de traitement induits par des IO. (
Nutanixbible.com)
Quand on regarde ce comparatif sur les différents temps moyens pris par les contrôleurs / HDD / SSD pour réaliser une action type que voit-on ?
Jusqu’à l’avènement de la consommation de masse du disque SSD, la latence disque était due pour une bonne part aux disques eux mêmes. Lorsque l’on réalisait le design d’une architecture, il fallait soigner particulièrement le nombre d’axes, les types de raid, le cache des contrôleurs, les QueueDepth des différents composants… bref le stockage était un bottleneck critique, dont le point central était le disque. D’autant plus qu’il représentait un gros investissement et un scaleout proche de zéro.
Le SSD a finalement mis la pression sur les contrôleurs des baies ainsi les contrôleurs réseaux/fabric FC qui deviennent les points de contention, le débit et la latence ayant été grandement augmentée.
L’hyperconvergence est donc apparue pour répondre à un besoin de simplification, de scaleout ET de performance (le stockage au plus proche du compute).
- Au final quels sont les bénéfice de l’hyperconvergence pour une IT ?
Si l’on reprend les différents points évoqués, c’est une véritable simplification de l’architecture doublée d’un scaleout prévisible et avec des paliers faible.
Pour reprendre l’exemple précédent : Si le manager de l’IT peut prédire avec l’équipe projet métier les besoins en terme d’infrastructure pour son projet et d’évaluer rapidement ce que cela va impliquer. S’il peut même commander le matériel en avance de phase (1, 2, 10 blocs), l’installer en quelques jours / semaines. Et au final si le projet peut monter en puissance sans impacter l’infrastructure et que l’infrastructure peut évoluer sans impacter les machines. N’est-ce pas le rêve pour le métier, le client et l’IT ?
En conclusion :
Dans ce billet j’ai pû introduire le sujet de l’hyperconvergence en douceur. Par la suite on va descendre petit à petit et plonger au coeur de la technique. Il ne me semble pas approprié de confronter les technologies sur leur performances pures. D’abord, les services marketing de ces sociétés font cela bien mieux que moi. Ensuite, il me semble plus pertinent regarder les différentes approches techniques, leur roadmap, la vision que j’en ai et leur intégration aux IT que je côtoie au quotidien depuis maintenant plus de 15 ans. Cette série d’article sera donc focalisée sur ces points :
- les potentialités,
- ce qu’il y a en dessous,
- Comment cela s’intègre aux autres éléments de l’ecosystème
- Comment cela s’intègre à une IT
Stay Tuned !
@virttom